What have we learned?
What we learned about Toxicity
How to define it
🟢 Non-toxic: Respectful and constructive. Does not contain personal attacks or offensive content.
🟡 Slightly Toxic: Although mostly respectful, it suggests a lack of appreciation for the viewpoints of others. It does not directly attack individuals or groups.
🟠 Moderately Toxic: Features a clearly disrespectful tone. Does not involve violent attacks.
🔴 Highly Toxic: Insulting and aggressive. Targets groups and individuals based on their gender, ethnicity, sexual orientation, ideology, or religion.
🔴 Extremely Toxic: In addition to the elements of highly toxic messages, this includes threats or calls to violent action.
In accordance with this definition, an online survey (N=300) was conducted with a sample of American participants, balanced by gender and political orientation (167 female, aged 40.69 ± 11.95 yr). The survey's primary objective was to assess individual perceptions of message toxicity within various Telegram channels. They were recruited through Prolific, an online research platform, and invited to complete the survey via SurveyMonkey. They were informed that their participation was completely voluntary and that they could withdraw their participation at any time without penalty.
Participants rated the toxicity of 30 messages (sourced from different Telegram channels) on the 5-point scale (0-4) mentioned before. Attention checks were incorporated to ensure data quality, and participants failing two or more of them were excluded from compensation. A £0.90 incentive was provided upon successful completion to encourage engagement and maintain data quality. We used the recollected data as ground truth for our classifier.
Multiple attributes in toxicity
An observation that we took from the literature is that polarizing or toxic content has different attributes that we believe are key to understanding unhealthy online conversations (Price et al., 2020).
We believe that both detecting and communicating these attributes are crucial components of a toxicity classifier. To help build this classifier we used the UCC dataset, a rich and annotated set of online comments.
Analyzing this dataset we realized some of the labeled attributes were similar and, as such, redundant.
Using Principal Components Analysis we determined that the most important attributes to detect are: sarcasm, antagonism, generalization and dismissiveness.
How to communicate it
As far as we know, there are no other toxicity classifiers that combine accurate and nuanced metrics with tailored and persuasive explanations of their classifications. Moreover, they do not showcase to the user healthier alternatives of communication.
What we learned about the technology
In our literature overview of existing toxicity detection models, we came to the conclusion that there are different technologies that have proven accurate for the task. The two main ones are outlined below.
When prompted effectively, generative LLMs are accurate classifiers for nuanced language tasks and can generate persuasive messages. However, they can be quite expensive, slow and memory intensive.
On the other hand, BERT models are often cheap to train and deploy and accurate, but they may struggle with nuanced classifications.
We concluded that leveraging these two classification tools can yield great results. We propose a classification pipeline that integrates these classifiers with the Telegram API to develop agents that interact smoothly with users. This setup makes it easy to fetch messages from public Telegram channels while preserving user privacy, as we do not know who sent the messages.
Choosing the right generative LLM
When choosing the right LLM for our project, we had many different angles to consider. First of all, as we wanted both the liberty to fine-tune the chosen model and the option to run inference of the LLM locally, we focused our search on small and effective open-source models. That being said, we had different tasks we needed the chosen LLM to excel at.
As we have stated before, in Detoxigram we use LLMs for different tasks.
For both explaining toxicity and detoxifying messages, we needed a model that is both efficient and easily adaptable to our specific problem. We believe Llama 3, as an open-source, efficient, small model, is perfect for our needs. There is also a very important factor to consider: when detoxifying messages, under no circumstances do we want to be accidentally generating hate speech ourselves. The emphasis Meta has put on ensuring Llama 3 is a relatively safe model, including the published resources for developers, has been an important factor when deciding to use this LLM for our project.
Moreover, the choice of an open-source model like Llama 3 aligns with our project's spirit of transparency and collaboration. Open-source models provide us with the flexibility to deeply understand the model architecture and make necessary adjustments that proprietary models might not allow. This is particularly important for us as we want to ensure our solution is robust and tailored to the nuances of Rioplatense Spanish.
What have we built?
In order to achieve this, we proposed a toxicity-detection pipeline that combines generative LLMs and BERT to exploit their strengths efficiently.
We decided to use the BERT-based classifiers for two different tasks:
- Coarse-grained toxicity detection of Telegram messages.
- Detecting unhealthy-speech attributes of the Telegram messages.
The purpose of the second task is to accurately demonstrate to users the various dimensions of unhealthy speech that a channel might exhibit. By providing specific information about the different dimensions of toxicity in Telegram messages, users can make more confident and informed decisions about the content they consume. For this task we trained a BERT-based classifier using the dataset mentioned in the previous section.
We decided to use generative LLMs for the following tasks:
- Fine-grained toxicity detection of telegram messages.
- Explaining to the user the reasons behind each classification.
- Detoxifying toxic messages.
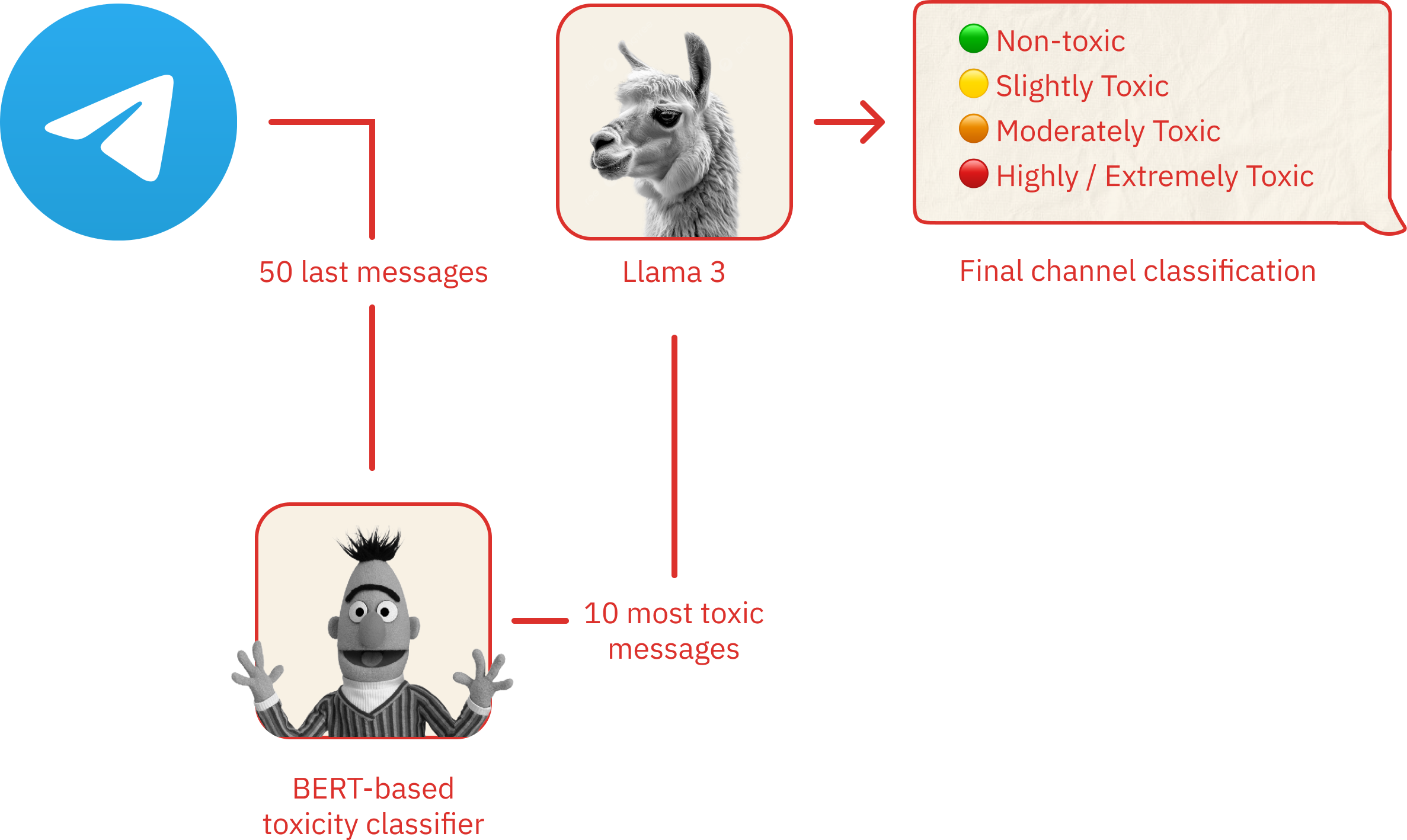
- We extract the last 50 messages of a given Telegram channel.
- We classify these messages using a BERT-based toxicity classifier.
- We then take the 10 most toxic messages from the previous step and we again classify them using a generative LLM. This ensures we accurately portray the toxicity of the Telegram channel.
- Finally we prompt the generative LLM to produce a short text explaining the classification of the Telegram channel, and we use the second BERT-based classifier to detect the toxicity attributes of the channel.
You can check our code here.
What can users do with Detoxigram?
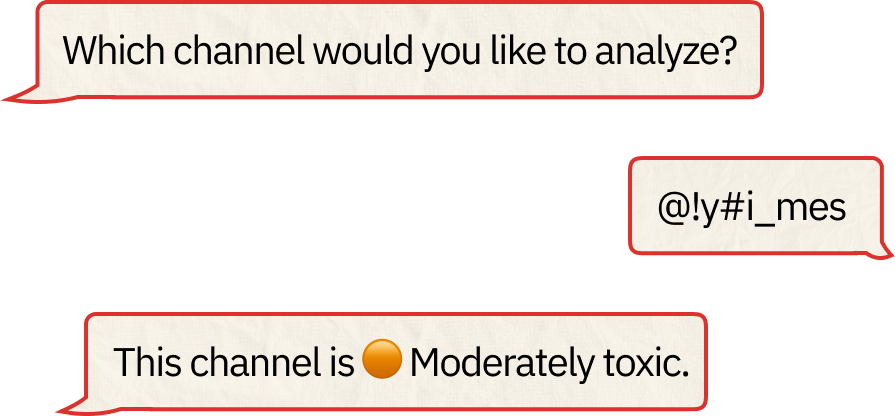
Analyze a Channel: users can use Detoxigram to analyze the toxicity level of any public Telegram channel. By simply inputting the channel name, our tool will scan and evaluate recent messages to provide a classification. This helps users understand the general tone and health of the conversations within the channel.



Main advantages of Detoxigram
Information is provided to the user gradually according to its requests. Our classifications are communicated in combination with an intuitive color code that works as a “traffic light” that synthesizes the classification.
Toxicity Dimensions are shown with an image that is coordinated with the color code matching the overall classification of the channel.
What are our plans for the future?
- Twitter Analyzer (Live beta): We've developed a real-time Twitter data analysis tool that provides detailed insights into the level of toxicity in a user's content. This helps to understand the implications of the content we consume in a very engaging way.
- Twitter Bot Integration: We aim to create a bot seamlessly integrated into Twitter, providing users with an intuitive way to interact with our platform, perform various tasks, and receive personalized recommendations on the content they consume.
- Fine-tuning of an LLM: To enhance the performance of our toxicity detection models, we're exploring the fine-tuning of a smaller LLM specifically for classification tasks in the context of text toxicity, aiming to achieve greater accuracy and efficiency.
- Scalability Enhancements: Recognizing the growing demand for our services, we're committed to scaling our infrastructure to support thousands of concurrent users. This involves optimizing our code, deploying load balancers, and leveraging cloud-based services to ensure high availability and performance.
- Expanding to WhatsApp: In addition to Twitter, we're considering deploying our functionalities into WhatsApp, enabling users to access our services more conveniently through a widely used messaging platform.
- Explore improving the performance of the LLM classifier: To enhance the performance of our toxicity detection models, we're exploring the fine-tuning of a smaller LLM specifically for classification tasks in the context of text toxicity, aiming to achieve greater accuracy and efficiency.
- API Development: Detoxigram API will empower developers to integrate our toxicity detection and moderation capabilities into their own applications.
References
- Nedjma Ousidhoum, Xinran Zhao, Tianqing Fang, Yangqiu Song, and Dit-Yan Yeung. 2021. Probing Toxic Content in Large Pre-Trained Language Models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4262–4274, Online. Association for Computational Linguistics.
- Paula Fortuna, Juan Soler-Company, Leo Wanner. How well do hate speech, toxicity, abusive and offensive language classification models generalize across datasets? 2021. Information Processing & Management, Volume 58, Issue 3, ISSN 0306-4573.
- Ilan Price, Jordan Gifford-Moore, Jory Flemming, Saul Musker, Maayan Roichman, Guillaume Sylvain, Nithum Thain, Lucas Dixon, and Jeffrey Sorensen. 2020. Six Attributes of Unhealthy Conversations. In Proceedings of the Fourth Workshop on Online Abuse and Harms, pages 114–124, Online. Association for Computational Linguistics.
- Zhixue Zhao, Ziqi Zhang, and Frank Hopfgartner. 2021. A Comparative Study of Using Pre-trained Language Models for Toxic Comment Classification. In Companion Proceedings of the Web Conference 2021.
- Hartvigsen, T., Gabriel, S., Palangi, H., Sap, M., Ray, D., & Kamar, E. (2022). Toxigen: A large-scale machine-generated dataset for adversarial and implicit hate speech detection. arXiv preprint arXiv:2203.09509.